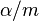Look at the following graph showing the averages and the corresponding error bars. Can we conclude whether the difference between the means of the two groups is statistically significant?

Well, the short answer is yes and no. A longer answer is, if the error bars provide the corresponding 95% confidence interval, the values in these two groups are normally distributed, then the difference is statistically significant at a 5% level using an unpaired t-test.
Now the long answer...
Let's choose 5% significance level, which is usually assumed when the significance level is not specified..
The answer? Still not definitive -- because error bars can represent different things. Some people simply plot the standard deviation of the sample, others use them to represent standard errors of the mean, and still others put confidence intervals there. Depending on the nature of the error bars, we may or may not be able to infer the statistical significance of the difference of the mean.
Some words on standard deviation, standard error of the mean, and the confidence interval. Standard deviation simply measures the variability of a data set, without considering the sample size. When the sample size is large enough, it is a good estimate of the population standard deviation. However, when we conduct a statistical test, we are usually investigating whether the means are different in the two groups. In that sense, the standard errors of the means are more informative.
The answer? Still not definitive -- because error bars can represent different things. Some people simply plot the standard deviation of the sample, others use them to represent standard errors of the mean, and still others put confidence intervals there. Depending on the nature of the error bars, we may or may not be able to infer the statistical significance of the difference of the mean.
Some words on standard deviation, standard error of the mean, and the confidence interval. Standard deviation simply measures the variability of a data set, without considering the sample size. When the sample size is large enough, it is a good estimate of the population standard deviation. However, when we conduct a statistical test, we are usually investigating whether the means are different in the two groups. In that sense, the standard errors of the means are more informative.

If data are normally distributed, the standard errors are less than the standard deviation $\sigma$ -- indeed, the standard error of the mean SEM = $\sigma / \sqrt{n}$. Now as

It is hard to tell. However, when we have the error bars represent the 95% confidence intervals, then we can conclude that the difference is statistically significant at 5% if the bars don't overlap. BUT, the opposite is not necessarily true---two 95% confidence intervals that overlap may be significantly different at the 95% confidence level.

What we can tell is whether the sample mean is statistically significant from a specific value by checking whether that value is within the confidence interval or not. For example, the sample mean is significantly different from 0 at 5\% level if and only if 0 is not contained in the 95% confidence interval.
The confidence interval is larger than the standard error bar -- $t_{(1+\alpha)/2}$ times the error bar width, where $t_{(1+\alpha)/2}$ represents the $\frac{1+\alpha}{2}$ quantile of a t-distribution. When the sample size is large, its value is approximately 1.96, which is the quantile for a normal distribution.
Therefore, we can easily conclude whether the difference is statistically significant when the error bars represent confidence intervals. If the error bars represent standard errors of the means, however, we can conclude that the difference is not statistically significant if they overlap.
P.S.: The meaning of a 95% confidence interval? Some people understand it as the population mean of the distribution is in the confidence interval with probability 0.95. Well, that is a wrong interpretation. The mean is a fixed value, it is either in that interval or not, and there is no randomness involved. The correct interpretation? Consider drawing the sample with the same size many times, and each time you have a 95% confidence interval. Then 95% of those confidence intervals (one for each sample) will cover the population mean -- in other words, the population mean falls into 95% of those confidence intervals.
P.P.S.: Sample s1 consists of 19 observations drawn from the normal distribution $N(5, 1^1)$, and sample s2 consists of 100 observations drawn from the normal distribution $N(6,2^2)$.
What we can tell is whether the sample mean is statistically significant from a specific value by checking whether that value is within the confidence interval or not. For example, the sample mean is significantly different from 0 at 5\% level if and only if 0 is not contained in the 95% confidence interval.
The confidence interval is larger than the standard error bar -- $t_{(1+\alpha)/2}$ times the error bar width, where $t_{(1+\alpha)/2}$ represents the $\frac{1+\alpha}{2}$ quantile of a t-distribution. When the sample size is large, its value is approximately 1.96, which is the quantile for a normal distribution.
Therefore, we can easily conclude whether the difference is statistically significant when the error bars represent confidence intervals. If the error bars represent standard errors of the means, however, we can conclude that the difference is not statistically significant if they overlap.
P.P.S.: Sample s1 consists of 19 observations drawn from the normal distribution $N(5, 1^1)$, and sample s2 consists of 100 observations drawn from the normal distribution $N(6,2^2)$.


 times what it would be if only one hypothesis were tested.
times what it would be if only one hypothesis were tested.